DigitalOcean так и остается хостингом для пет-проектов
Digital Ocean – это такой облачный хостинг, который любят за недорогие цены на небольшие виртуалки для дев целей и прикольные мануалы. Они очень пытаются быть модными и крутыми, делая всякие маркетплейсы с готовыми сборками разных утилит, предлагая функциональные кластера Кубера, вводя в линейку memory-optimized сервера, позволяя создавать отдельные приватные сети для конкретных машин, создвать теги и называя свои сервера Дроплетами. Под словом пытаются я хочу сказать, что сами они себя ставят в один ряд с AWS и GCM. Но нельзя просто так взять и стать топовым облачным провайдером. На собственном примере расскажу, почему меня в этом не убедили.
О чем это я
Я не буду томить долгими рассказами и сразу озвучу главную мысль. Самое главное в сервисах, которые пытаются быть гибкими и оказывать качественные услуги сложнее интернет-магазина с самовывозом – это саппорт и фидбек о текущем состоянии услуг. Это особенно актуально для виртуализированных ресурсов, где клиент не имеет возможности вообще понять, что на самом деле происходит с его серверами. Для меня облачные сервера всегда значили, что они слабее выделенного сервера в реальном ДЦ и с этим не было проблем, это логично. Но смысл облачных серверов в том, чтобы проблемы с железом решались на том же уровне – там где я вообще не вижу, что происходит. К чему это я.
Расскажу про четыре проблемы, с которыми столкнулся один из моих проектов, когда превратился из небольшой апки с пару тысячей юзеров в день в более-менее нагруженное приложение, где все девелоперы по утрам в офисе рвут на себе волосы на голове и не понимают какую часть сегодня взяться оптимизировать и рефакторить.
1 и 2 случаи
БД начинает много писать и читать. Быстро упростить нагрузку и не накосячить не получится, нужно немного пожить в этом состоянии – иопсы под потолок, цпу скачет туда-сюда каждый вечер, слегка рисуя iowait. Сервер ресайзить нет смысла, вся нагрузка упирается в диск. Хотелось бы отключить логи и снизить нагрузку на диск, но логи были нужны. Решение было очевидное – подключить еще один диск, писать логи в него. Так и сделали – хорошо живем, вроде чуть попроще стало. Как-то раз девелопер решает зафигачить большой-большой запрос по логам, который он делал и раньше. Бамс основной диск ложится. “Но ведь это два разных диска!” – говорили они мне. Оказывается, не особо. Я сейчас уже этот момент на графиках в истории на найду, но там было видно, как подскочили показатели сразу двух дисков одновременно и вернулись, как только запрос отменили. Ну, штош, решили пока не делать таких запросов.
Прошло пару дней и внезапно диски упали вообще. CPU показал 99% iowait, записи и чтения нет, сервер сам доступен. Опытным путем выяснили, что проблема с диском логов – база не может записать лог и валится. Сервер уходит в ребут – нет эффекта, через пару минут тоже самое. Выключили сервер через дашборд DO и включили. Ожило, но ненадолго. Чтобы понимать, выключаются “жирные” сервера всегда долго, поэтому до факта самого отключения может пройти и минут 6-7, а потом еще пару минут до запуска, то еще удовольствие. Решили отсоединить диск полностью и выключить логи, чтобы хоть что-то работало. Снова ребут – все работает. Ну, ок, больше не экспирементируем с разделением дисков, уговорили.
Что примечательно, когда я почти сразу расписал эту ситуацию саппорту, объяснив, что как-то не очень хорошо, когда мы теряем критические компоненты сервиса с неуловимыми косяками. Мне ответили на следующий день, часов через 16. Ответ классный:
We are sorry to hear you are seeing issues accessing that volume. In this case can you try detaching that volume, powering the droplet off, attaching it again then powering it back on. Please then run a file system check on that volume to be sure that there are not file system errors there causing issues.
Спасибо. Дальше я что-то писать не стал, понятно, что всем пофигу.
Второй раз повторилось примерно тоже самое. Давайте вспомним, что у нас уже один диск как и было раньше, все должно быть хорошо. Но через еще четыре дня снова прилег диск, но только теперь сразу был 99% iowait, а никакие ребуты не помогали. Получается, мы убили этот сервер) В этот раз мы просто переключились на реплику, она стала новым мастером. Старый Дроплет очнулся только через час! Удалили и забыли.
Выводы: что два диска, что один диск, обе этой херни сами понимаете что. Я писал в сапорт, чтобы они хоть как-то разобрались или сказали бы, что что-то пошло не так. Но мы до сих пор не знаем, ни что пошло не так, ни что толком делать, если повторится, кроме как менять дроплет.
3 случай
Это не то чтобы косяк и, наверное, надо было сразу читать документацию, но нормальные поцоны же не в курсе, что это. У DO есть так называемые Spaces – файловые хранилища по типу S3 бакетов Амазона. Собственно, это полный аналог с таким же апи, но одним небольшим отличием. У этих бакетов есть https://www.digitalocean.com/docs/spaces/ лимиты. Лимиты на операции записи, удаление и даже на объем загружаемого за день:
Spaces have the following request rate limits:
750 requests (any operation) per IP address per second to all Spaces on an account
150 PUTs, 150 DELETEs, 150 LISTs, and 240 other requests per second to any individual Space
2 COPYs per 5 minutes on any individual object in a Space
И бла-бла-бла. Я могу ошибаться, но на Амазоне такого нет. Это как по мне полный идиотизм и вот почему. В моем понимании все эти бакеты созданы для того, чтобы клиент не морочился с поддержкой своего хранилища. Оно просто существует где-то, что-то делает. Заливай, отдавай. Я думаю можно прекрасно предположить, что в более-меннее крупном сервисе 150 путов в секунду это вообще не много. Наверное, действительно крупный сервис уже задумался о распределении таких нагрузок, хотя казалось бы зачем, если платишь за готовое решение. Но ирония в том, что это действительно очень мало.
Традиционно, мы хранили там статику. Весь контент, который аплоудили юзеры, уходил туда. И вот мы решили залить множество небольших файлов, обновить много контента и нахреначили скрипт, который заливал кучу мелких картинок в этот бакет. В какой-то момент эти операции просто начали упираться в лимиты, что скрипт, конечно, игнорировал, ибо о такой штуке никто даже не подумал. Я увидел проблему, когда пару юзеров не смогли загрузить себе аватарочку:
An error occurred (SlowDown) when calling the PutObject operation (reached max retries: 4): Please reduce your request rate.
После этого скрипт остановили, ограничили его скорость, и все стало хорошо. Это все же глупость. Раз и есть лимиты, могли бы хотя бы о них предупреждать при создании бакетов, это же важный аспект. Так же я бы не отказался от платного расширения этих лимитов. Бакет сам по себе достаточно не дорогой, поэтому это можно было бы оправдать, если бы была возможность исправить это. Я ведь не удивлюсь, если лимит существует не на бакет, а на аккаунт, и создание нескольких не поможет.
4 случай
И снова проблема бакета. Я просто оставлю это здесь:
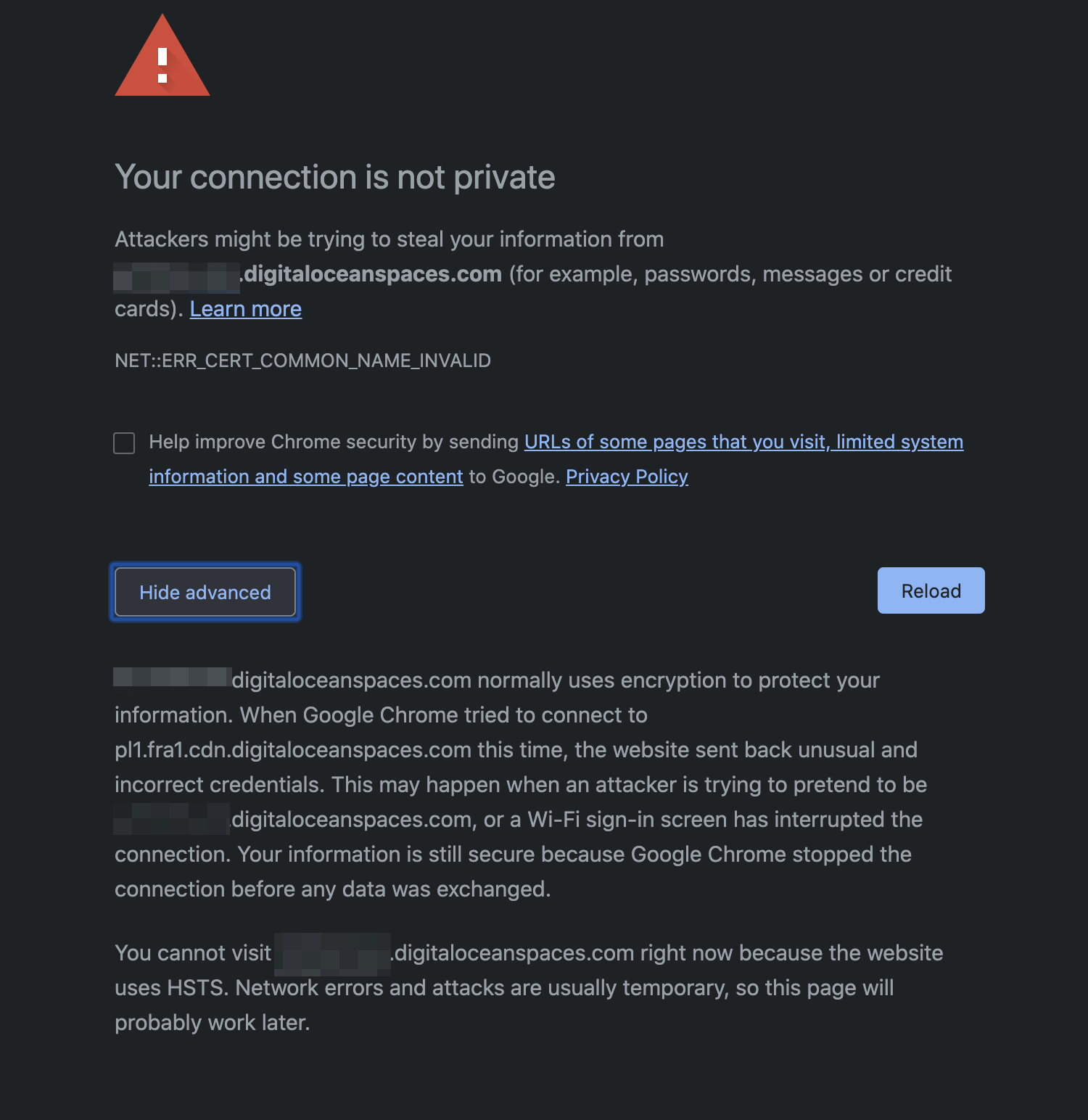
Просто взять и просрать сертификат к сервису на ровном месте. По истории инцидента видно, что проблема исправилась через час, но на деле сам инцидент был создан минут через 30 после того как у всех отвалились картинки. Опытным путем выяснили, что проблема была только на CDN адресе, а по обычному работало, и мы быстро переключились. Поэтому не сильно пострадали, но, как можно понять, вся статика у юзеров просто перестала отображаться, потому что клиенты не будут ничего загружать без SSL.
Что имеем
Имеем, что я однозначно буду советовать всем уезжать с DO, когда есть понимание, что проект сталкивается с большими нагрузками. Что будет происходить, если бы мы увеличились в наших RPS раза в три, я даже боюсь представить. Я уже молчу про аномальные сетевые ошибки, которые происходят периодами раз в пару дней, которые вообще никак толком не отловить.
DO идеален, чтобы поднять себе какой простенький впн (скачка торентиносов там, кстати, очень жестко палится, сразу приходят авто-страйки от правообладателей), хостить там свой сайт, на который никто кроме вашей мамы не заходит, или играться с новыми технологиями. У них много классных штук, тот же интерфейс дашбода вряд ли у кого-то найдется лучше, но внешний вид и исполнение все же принципиально разные вещи, а особенно в данном случае.
Я могу ошибаться, может это были частные случаи, но мой опыт таков. Пока писал этот текст, нашел, что существует Premier Support. Попробую узнать прайс и попробовать, может мой мир станет лучше.